Datos e información en Inteligencia Artificial
En este artículo proponemos el análisis del tratamiento de entrenamiento de un sistema de IA basado en aprendizaje automático y redes neuronales.

Foto de Matt Wang en Unsplash.
En sistemas de Inteligencia Artificial basados en aprendizaje automático, la aplicación efectiva de los principios de responsabilidad proactiva, de minimización y exactitud, la protección de datos desde el diseño, y el análisis de idoneidad están vinculados a la utilización de metodologías de desarrollo maduras. Estas han de determinar las medidas técnicas y organizativas apropiadas para garantizar y poder demostrar de forma objetiva el cumplimiento del RGPD. Para ello es necesario recurrir a profesionales de la ciencia de datos y poner en prácticas las técnicas ya consolidadas de la ingeniería y matemática. La selección de una tecnología u otra, un modelo concreto, datos de entrenamiento y metodologías, no puede ser arbitraria o limitarse a la última tendencia tecnología.
En este artículo proponemos el análisis del tratamiento de entrenamiento de un sistema de IA basado en aprendizaje automático y redes neuronales. Este caso es un ejemplo muy sencillo de IA, con propósitos didácticos, que determina si una persona tiene sobrepeso. Para ello toma en cuenta solo dos variables, altura y peso. Es decir, un sistema de IA que sea capaz de clasificar entre aquellos que tienen sobrepeso y aquellos que no lo tienen.
El ejemplo plantea si una red de una sola neurona podría ser lo suficientemente inteligente para resolver el problema. Incluso con una neurona muy sencilla.
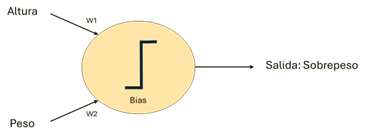
Figura 1: La neurona del ejemplo se configura con parámetros (Bias, W1, W2) y realiza una sencilla función, Resultado = Bias + Altura * W1 + Masa * W2, de forma que si el Resultado es positivo se obtiene como Salida el valor 1 (sobrepeso) y si no el valor 0 (no hay sobrepeso)
Para ajustar los parámetros de la neurona hay que conseguir muestras para los algoritmos de entrenamiento. Estas muestras se pueden conseguir de personas reales, tomando los datos de altura, peso y estimación de sobrepeso. Pero también se podrían conseguir las muestras generándolas a partir de una tabla de peso ideal (datos sintéticos).
La primera cuestión es cuántas muestras deberíamos conseguir para el tratamiento de entrenamiento. En este caso vamos a elegir sólo tres muestras y comprobaremos si es posible obtener un sistema IA con solo una neurona: [(185cm, 80kg, NoSobrepeso), (160cm, 70kg, Sobrepeso), (190cm, 100kg, Sobrepeso)]. Adelantamos que el resultado es positivo, es posible conseguirlo, siempre que se elijan las muestras adecuadas (calidad del conjunto de datos). Una red neuronal formada por una única neurona sencilla permite dividir todas las posibles muestras en dos conjuntos separados por una línea recta, es decir, definir una relación lineal entre lo que es sobrepeso y lo que no lo es.
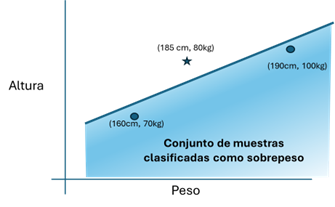
Figura 2: Las muestras marcadas como una estrella son las de no-sobrepeso y las mostradas con un círculo las muestras clasificadas como sobrepeso. La neurona inferirá que todas las muestras que queden por debajo de la línea serán clasificadas como sobrepeso. Cuando se somete el sistema ya entrenado a un conjunto de muestras de prueba podemos comprobar que funciona razonablemente bien.
Sin embargo, supongamos que un modelo de red con una neurona no parece lo suficientemente listo. Vamos a entrenar un modelo IA más complejo, más inteligente, en este caso con niveles de cinco neuronas complejas y con una profundidad de cinco niveles.
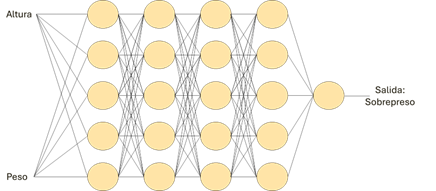
Figura 3: En este caso, tendremos un total de 21 neuronas y, además, cada una de ellas, más compleja. Existen otras estructuras de aprendizaje automático más complejas, que encadenan distintas redes neuronales, como los transformers.
En este caso, con solo tres muestras para el entrenamiento, y depende de cómo se parametrice el algoritmo de aprendizaje, una de las posibles soluciones podría ser la siguiente:
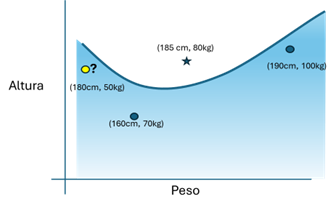
Figura 4: Posible resultado del ajuste de una red más compleja, en la que no hay una división lineal del espacio de muestras, de forma durante las proporciona resultados erróneos (una alucinación) marcada en amarillo.
Al ser la red más inteligente, permite dividir todo el conjunto de posibles muestras de forma más compleja que solo con una relación lineal. En este caso, el modelo así entrenado tendría lo que en generación de texto se denominarían “alucinaciones”, como considerar que una persona de 180cm y 50kg tiene sobrepeso.
Para evitar esta alucinación, sería necesario utilizar muchas más muestras en el proceso de entrenamiento. Por ejemplo, en vez de tres, sería posible conseguir 23 muestras de distintas personas como estas:
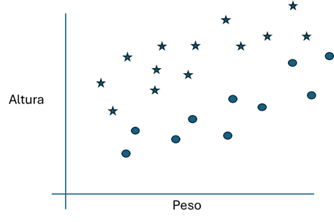
Figura 5: Posible conjunto de entramiento en el que con círculos se representa a las muestras etiquetadas como sobrepeso.
Un resultado posible después del tratamiento de entrenamiento podría ser el siguiente:
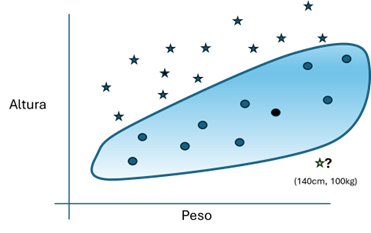
Figura 6: En esta posible solución, la alucinación está marcada en amarillo, y las muestras irrelevantes para el aprendizaje en negro.
Este resultado es posible por la gran inteligencia de la red que se está entrenando, la cual permite establecer clasificaciones más complejas que aquellos que son posibles con una única neurona. El problema es que con este resultado también aparecen alucinaciones, como el clasificar a una muestra de 140cm y 100kg como no-sobrepeso. Para resolverlo, sería necesario conseguir más muestras que podrían ser excepcionales en el mundo real, bien consiguiendo más muestras reales o creando más muestras sintéticas seleccionadas.
¿Qué primeras conclusiones podríamos sacar de este ejemplo?
La red de una sola neurona funciona mejor en este ejemplo, no por ser sencilla, sino porque el propio diseño de la red incluye información implícita sobre el contexto del tratamiento para un propósito determinado. Dicha información, implícita en la propia estructura de la red, consiste en que la relación entre altura y peso con relación a la evaluación del sobrepeso es cuasi-lineal.
La red más inteligente carece de esa información desde el diseño. Por lo tanto, es necesario utilizar muchas más muestras para que el proceso de entrenamiento infiera esa relación cuasi-lineal y, sino dispone de muestras adecuadas en el proceso de entrenamiento, presenta problemas de idoneidad (las alucinaciones).
En este artículo se están presentando dos formas distintas de trabajar. En la primera, se ha realizado un análisis de la relación entre los datos con relación al propósito del tratamiento (relación cuasi-lineal). A continuación, se ha introducido dicha información en la estructura de la red como un conocimiento a priori (una estructura con una neurona). Después, se han seleccionado muestras con la calidad necesaria para optimizar el tratamiento de entrenamiento para introducir el conocimiento a posteriori.
En la segunda forma de trabajar, se ha elegido una red que permita representar cualquier relación posible, entrenándola con todas las muestras disponibles. El ejemplo extremo sería el haber utilizado un modelo generativo para el mismo propósito.
La primera forma de trabajar tiene ventajas, como la economía de datos, en recursos de tratamiento y en tiempo de entrenamiento y test, así como una forma más objetiva de evaluar la calidad del dato de salida. Tiene inconvenientes, como la necesidad de utilizar una metodología de desarrollo más madura y que requiere emplear desde el diseño profesionales de ciencia de datos que empleen técnicas de análisis estadístico, algebraicas, numéricas, de investigación operativa, teoría de la información, etc., o incluso prototipos basados en aprendizaje automático, para determinar la estructura de aprendizaje automático más adecuada.
La segunda forma de trabajar tiene otra serie de cualidades, como obviar una metodología madura de desarrollo, los procesos de ingeniería desde el diseño, un proceso de toma de decisiones de diseño basado en la evidencia, la necesidad de recoger una cantidad no conocida a priori de muestras de entrenamiento y test, la incertidumbre de los tiempos de desarrollo, prueba, y la falta de garantías de calidad del dato de salida.
La cuestión no es si elegir la estructura de aprendizaje automático más sencilla o más compleja, ni si la clasificación es lineal o no. La cuestión es elegir aquella que es más adecuada al contexto y al propósito de la operación en el tratamiento. Un conocimiento previo, obtenido por el análisis desde el diseño, es posible trasladarlo a la estructura de la IA, permite ahorrar muchos recursos en desarrollo (en particular en número de muestras y datos por muestra) y tener más garantías de calidad en el resultado.
Estas conclusiones tienen implicaciones en protección de datos.
Con relación a los principios de minimización y exactitud, así como de protección de datos desde el diseño, vemos que el primer ejemplo solo necesita de tres muestras correctamente elegidas. Es decir, tres muestras de calidad, aunque sean inventadas (sintéticas). La calidad del dato y la calidad del conjunto de datos en aprendizaje automático no es tanto que sean fuentes de datos exactos, sino que sean relevantes para conseguir el propósito de entrenar adecuadamente el modelo.
Con relación al principio de responsabilidad proactiva y a la protección de datos desde el diseño, vemos que es necesario que se utilicen metodologías de desarrollo maduras que garanticen, en el momento de determinar los medios de tratamiento como en el momento del propio tratamiento, medidas técnicas y organizativas apropiadas basadas en decisiones objetivas.
Con relación a la idoneidad del tratamiento surgen dos cuestiones. La primera con relación al ámbito del tratamiento en el que se va a utilizar dicho sistema de IA en explotación como una de las operaciones del mismo, junto con otros sistemas. Y es si la salida de la IA cumple con garantías de calidad para casos no contemplados en el conjunto de entrenamiento o test, o que incluso el propio proceso de entrenamiento los ignore.
La segunda cuestión de idoneidad sería sobre el tratamiento de entrenamiento y prueba, y el hecho de que el tipo de estructura elegida requiera tal cantidad de muestras y de tal diversidad que no sea posible conseguirlas, o que no sea proporcional o legítimo recabarlas. De esta forma, el tratamiento no sería idóneo porque desde el diseño no se podría conseguir el propósito del mismo.
El ejemplo anterior es muy sencillo y los problemas habituales que se pretenden resolver con IA son mucho más complejos. No sería tan sencillo representar el conjunto de muestras en dos coordenadas para sistemas de decisión, sino que sería necesario usar 4, 10,100.000 o más dimensiones. Más aún en el caso de sistemas de generación de texto, imagen, etc. Pero para dicho análisis está la ciencia de datos y las herramientas antes señaladas, así como las metodologías de desarrollo que ya se aplican en otras disciplinas.
Este post está relacionado con otros materiales publicados desde la División de Innovación y Tecnología de la AEPD, como son:
- 10 Malentendidos sobre el Machine Learning (Aprendizaje Automático)[sep 2022]
- Requisitos para Auditorías de Tratamientos que incluyan IA [ene 2021]
- Adecuación al RGPD de tratamientos que incorporan Inteligencia Artificial [feb 2020]
- Evaluación de la intervención humana en las decisiones automatizadas [mar 2024]
- Sistema de Inteligencia Artificial: ¿solo un algoritmo o varios algoritmos? [nov 2023]
- Inteligencia artificial: Transparencia [sep 2023]


