Data and information in Artificial Intelligence
In this article we propose the assessment of the training processing of an AI system based on machine learning and neural networks.

Photo of Matt Wang in Unsplash.
In machine learning-based AI systems, the effective application of the principles of accountability, minimization and accuracy, data protection by design, and efficiency assessment are linked to the use of mature development methodologies. These must determine the appropriate technical and organisational measures to guarantee and be able to objectively demonstrate compliance with the GDPR. To do this, it is necessary to turn to data science professionals and put into practice the already consolidated techniques of engineering and mathematics. The selection of one technology or another, a particular model, training data and methodologies, cannot be arbitrary or limited to the latest technology trend.
In this article we propose the assessment of the training processing of an AI system based on machine learning and neural networks. This case is a very simple example of AI, for teaching purposes, that determines if a person is overweight. To do this, it takes into account only two variables, height and weight. That is, an AI system that is capable of classifying between those who are overweight and those who are not.
The example raises whether a network of a single neuron might be smart enough to solve the problem. Even with a very simple neuron.
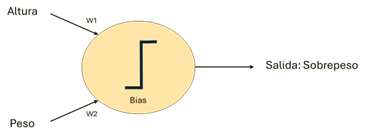
Figure 1: The neuron in the example is configured with parameters (Bias, W1, W2) and performs a simple function, Result = Bias + Height * W1 + Mass * W2, so that if the Result is positive, the value 1 (overweight) is obtained as Output and if not the value 0 (there is non-overweight)
To adjust the parameters of the neuron, samples must be obtained for the training algorithms. These samples can be obtained from real people, taking the data of height, weight and overweight estimate. But samples could also be obtained by generating them from an ideal weight table (synthetic data).
The first question is how many samples we should get for the training processing. In this case we are going to choose only three samples and we will check if it is possible to obtain an AI system with only one neuron: [(185cm, 80kg, Non-overweight), (160cm, 70kg, Overweight), (190cm, 100kg, Overweight)]. We anticipate that the result is positive, it is possible to achieve it, provided that the appropriate samples are chosen (quality of the dataset). A neural network formed by a single simple neuron allows all possible samples to be divided into two sets separated by a straight line, that is, to define a linear relationship between what is overweight and what is not.
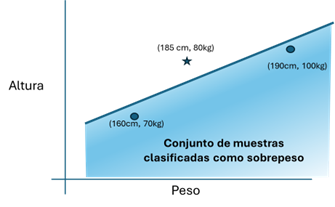
Figure 2: Samples marked as a star are non-overweight and those circled are those classified as overweight. The neuron will infer that all samples below the line will be classified as overweight. When the already trained system is subjected to a set of test samples, we can verify that it works reasonably well.
However, suppose a network model with a neuron doesn't look "smart" enough. We are going to train a more complex, "smarter" AI model, in this case with levels of five complex neurons and with a depth of five levels.
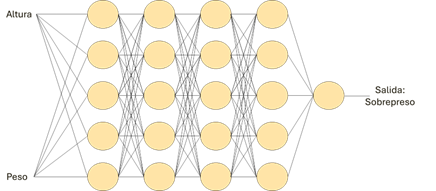
Figure 3: In this case, we will have a total of 21 neurons and, in addition, each of them more complex. There are other, more complex machine learning structures, which chain different neural networks, such as transformers
In this case, with only three samples for training, and depending on how the learning algorithm is parameterized, one of the possible solutions could be the following:
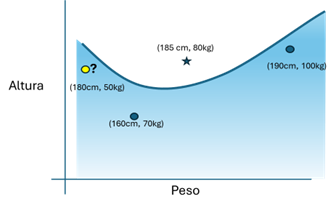
Figure 4: Possible result of fitting a more complex lattice, in which there is no linear division of the sample space, so that it outputs wrong results (one hallucination) marked in yellow.
As the network is the most "intelligent", it allows the entire set of possible samples to be divided in a more complex way than with just a linear relationship. In this case, the model thus trained would have what in text generation would be called "hallucinations", such as considering that a person of 180cm and 50kg is overweight.
To avoid this "hallucination", many more samples would need to be used in the training process. For example, instead of three, it would be possible to get 23 samples from different people like these:
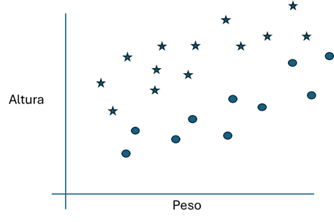
Figure 5: A possible training set in which circles represent samples labelled as overweight.
A possible outcome after training processing could be as follows:
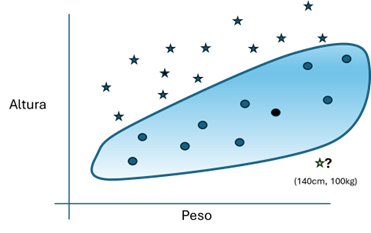
Figure 6: In this possible solution, the hallucination is marked in yellow, and the samples irrelevant to learning in black.
This result is possible because of the "high intelligence" of the network being trained, which allows for more complex classifications than those that are possible with a single neuron. The problem is that with this result "hallucinations" also appear, such as classifying a sample of 140cm and 100kg as non-overweight. To solve this, it would be necessary to obtain more samples that could be exceptional in the real world, either by obtaining more real samples or by creating more selected synthetic samples.
What first conclusions could we draw from this example?
The single-neuron network works best in this example, not because it is simple, but because the network design itself includes implicit information about the context of the processing for a given purpose. This information, implicit in the structure of the network itself, consists of the fact that the relationship between height and weight in relation to the evaluation of overweight is quasi-linear.
The "smarter" grid lacks that information by design. Therefore, it is necessary to use many more samples for the training process to infer this quasi-linear relationship and, if it does not have adequate samples in the training process, it presents problems of suitability (the "hallucinations").
Two different ways of working are being presented in this article. In the first, an analysis of the relationship between the data and the purpose of the processing (quasi-linear relationship) has been carried out. This information has then been introduced into the structure of the network as a "priori" knowledge (a structure with a neuron). Then, samples with the necessary quality have been selected to optimize the training processing to introduce the knowledge "a posteriori".
In the second way of working, a network has been chosen that allows representing any possible relationship, training it with all the available samples. The extreme example would be to have used a generative model for the same purpose.
The first way of working has advantages, such as data economy, in processing resources and in training and testing time, as well as a more objective way of evaluating the quality of the output data. It has "drawbacks", such as the need to use a more mature development methodology and that requires employing data science professionals from the design who use techniques as statistical analysis, algebraical, numerical, operational research, information theory, etc., or even prototypes based on machine learning, to determine the most appropriate machine learning structure.
The second way of working has another series of qualities, such as ignoring a mature development methodology, engineering processes from design, an evidence-based design decision-making process, the need to collect an unknown a priori number of training and test samples, the uncertainty of development times, evidence, and the lack of quality guarantees of the output data.
The question is not whether to choose the simplest or most complex machine learning structure, nor whether the classification is linear or not. The question is to choose the one that is most appropriate to the context and purpose of the operation in the processing. Previous knowledge, obtained by analysis from design, can be transferred to the structure of AI, allows saving many resources in development (in particular in number of samples and data per sample) and having more quality guarantees in the result.
These findings have implications for data protection.
In relation to the principles of minimization and accuracy, as well as data protection by design, we see that the first example only needs three correctly chosen samples. That is, three quality samples, even if they are invented (synthetic). Data quality and dataset quality in machine learning is not so much that they are accurate data sources, but that they are relevant to achieving the purpose of properly training the model.
With regard to the principle of accountability and data protection by design, we see that it is necessary to use mature development methodologies that guarantee, at the time of determining the means of processing and at the time of the processing itself, appropriate technical and organisational measures based on objective decisions.
In relation to the efficiency of the processing, two questions arise. The first is in relation to the scope of the processing in which the AI system in operation is going to be used as one of its operations, together with other systems. And that is whether the output of the AI complies with quality guarantees for cases not contemplated in the training or test set, or that even the training process itself ignores them.
The second question of efficiency would be about the training and testing processing, and the fact that the type of structure chosen requires such a large number of samples and of such diversity that it is not possible to obtain them, or that it is not proportional or legitimate to collect them. In this way, the processing would not be ideal because the design could not achieve its purpose.
The above example is very simple and the common problems that are intended to be solved with AI are much more complex. It would not be so simple to represent the set of samples in two coordinates for decision systems, but it would be necessary to use 4, 10,100,000 or more dimensions. Even more so in the case of text, image, etc. generation systems. But for this assessment there is data science and the tools mentioned above, as well as development methodologies that are already applied in other disciplines.
This post is related to other materials published by the Innovation and Technology | AEPD, such as:
- 10 Misunderstandings about Machine Learning [sep 2022]
- Audit Requirements for Personal Data Processing Activities involving AI [jan 2021]
- GDPR compliance of processing that embed Artificial Intelligence. An introduction [feb 2020]
- Evaluating human intervention in automated decisions [mar 2024]
- AI System: just one algorithm or multiple algorithms? [nov 2023]
- Artificial Intelligence: Transparency [sep 2023]


