Federated Learning: Inteligencia Artificial sin comprometer la privacidad
Las Privacy Enhancing Technologies (PET) permiten compartir asegurando los principios de protección de datos y también generan confianza entre los diferentes actores. Las técnicas de Aprendizaje Federado son una categoría de PET que permiten el desarrollo de sistemas de aprendizaje automático sin necesidad de comunicar los datos personales entre los intervinientes. Estas técnicas pueden ser tanto de tipo horizontal como vertical y son clave en los nuevos escenarios que se plantean como, por ejemplo, los Espacios de Datos.
Los datos generados por la actividad individual y empresarial tienen un gran valor que va más allá de lo económico. El combinar y utilizar datos de manera responsable es esencial para temas tan dispares como intentar predecir una enfermedad o diseñar productos y servicios. Por su gran potencial, es necesario controlar que sean utilizados para el beneficio de la sociedad. Mantener el control de la información que se puede generar a partir de los datos de las AAPP, las empresas y los ciudadanos es esencial para preservar nuestro modelo de derechos y libertades. Dicho control también es fundamental para generar confianza a entidades que tienen grandes repositorios de datos, ya que podrán determinar quién y para qué los está empleando sin que sus secretos comerciales e industriales se expongan, y con garantías técnicas de que se empleen para las finalidades declaradas.
Las Privacy Enhancing Technologies, en adelante PETs, son un conjunto de técnicas de computación que permiten analizar datos manteniendo la privacidad y el control sobre estos. Las PETs permiten explotar la información de forma sostenible y proteger los derechos fundamentales, por lo que son esenciales para el desarrollo económico. Y entre las estrategias y técnicas PETs figuran las arquitecturas de Federated Learning o aprendizaje federado.
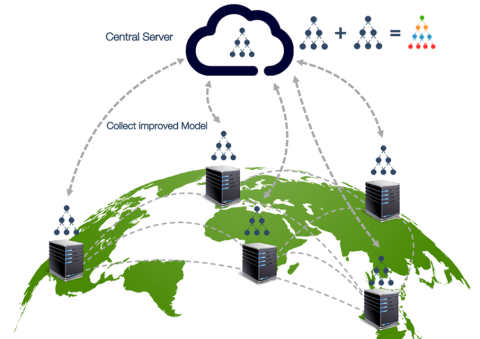
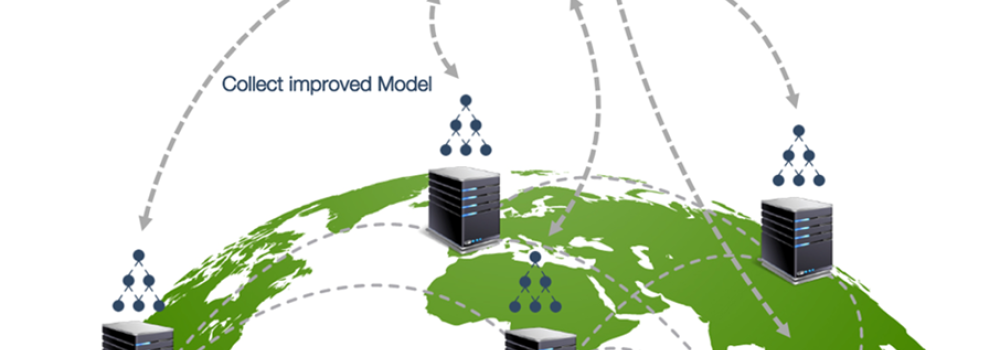
Figura 1: Entrenamiento Federado en el que se envían los modelos a los silos de datos. Cortesía de Acuratio
El Aprendizaje Federado habilita la creación de modelos de aprendizaje automático (Machine Learning) con un cambio de paradigma: en vez de centralizar los datos en un gran repositorio para analizarlos, se envían modelos al lugar donde están ubicados los datos. Esta estrategia, del tipo “compute-to data”, permite un tratamiento local de los datos para, posteriormente, agregar el resultado de los modelos parciales desarrollados y consolidar la información obtenida del aprendizaje en un modelo completo. De esta forma, habilita la creación de espacios federados de datos en los que cada participante mantiene el control, la soberanía y preserva la protección de los datos, eligiendo en todo momento quién puede hacer uso de los datos y para qué caso de uso en particular.
En el año 2017 se comenzaron a realizar las primeras pruebas a gran escala de Federated Learning mediante el envío de un algoritmo a millones de teléfonos móviles de pequeños modelos que aprenden de lo que escribe cada usuario en su teclado. La función de estos modelos era sugerir o predecir la siguiente palabra que se escribe en un chat. La diferencia fundamental entre esta técnica y lo que se venía haciendo hasta entonces radicaba en que las conversaciones privadas ya no se enviaban ya a un servidor central. En este caso eran los modelos los que se enviaban a los dispositivos de los usuarios, proporcionando privacidad y a la vez obteniendo resultados mucho mejores que los que había hasta entonces.
Este tipo de aprendizaje se encuadra dentro del llamado Aprendizaje Federado Horizontal y funciona muy bien con múltiples dispositivos distribuidos que generan datos similares. Conceptualmente la idea es muy sencilla: aprendamos de cada dispositivo y hagamos una media de los modelos entrenados.
Existen otros escenarios en los que distintas entidades recogen características distintas de un mismo individuo y es necesario ponerlas en común. Como ejemplo se pueden referenciar los sistemas de salud donde los datos de una misma persona podrían estar segregados en silos de datos: por ejemplo, unas instituciones podrían almacenan parte del historial clínico y otras algunos tipos de pruebas más específicas. Para enseñar a un algoritmo a detectar, por ejemplo, un tipo específico de cáncer a través de dichas pruebas, sería interesante combinar las distintas fuentes de datos del mismo paciente. El Aprendizaje Federado Vertical puede resolver esta situación, y tanto en Europa como en EEUU este tipo de técnicas están siendo intensamente estudiadas.
Para poder desarrollar un modelo de Aprendizaje Federado Vertical el primer paso consiste en encontrar a los pacientes que distintas instituciones tengan en común. Para no compartir los nombres ni ningún otro identificador, se pueden emplear técnicas basadas en computación segura multi-parte (por ejemplo private set intersection). A continuación, cada entidad dispondrá de una red neuronal que va a procesar sus datos de forma local, red que podría ser proporcionada por un tercero. Empleando estas redes neuronales locales sobre los datos conseguirán transformarlos hasta convertirlos en una representación que preserva la información que es necesario obtener. Esta información no son los datos originales, de forma que no se puede re-identificar al sujeto de los datos o interesado.
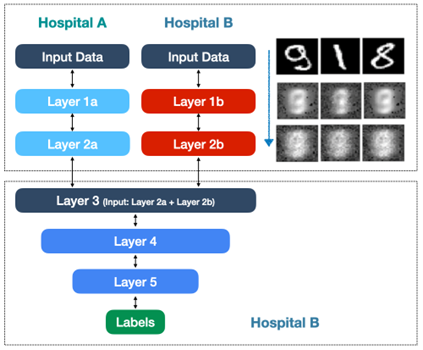
Figura 2: Modelo vertical con dos entidades en el que se anonimizan los datos para luego agregar de forma anónima los resultados de los modelos parciales. Cortesía de Acuratio
A continuación, las salidas de las redes locales se agrupan de forma anónima y se introducen en una tercera red neuronal que es la que realizará las predicciones o inferencias. Esta parte de la red neuronal nunca tiene acceso a los datos de los pacientes, recibe datos procesados por cada uno de los hospitales y computa las inferencias a partir de estos. Equivale a que las distintas redes hubieran desarrollado un idioma propio en el que pueden comunicarse pero que no puede entender un observador externo ni es posible la reidentificación del interesado. El resultado obtenido es idéntico al que se obtendría con un procesamiento centralizado.
Este Aprendizaje Federado Vertical puede ser complementado con otras técnicas que pueden ayudar a eliminar el sesgo (técnicas no-peek), con técnicas de split learning, que mejoran la capacidad de computación, o incluso de pooling, que mejoran la seguridad del procedimiento.
En conclusión, el modelo final de Aprendizaje Federado Vertical se compone de múltiples elementos: las redes locales de cada entidad y la red que hace las predicciones. Para realizar cualquier inferencia es necesario que las entidades colaboren de forma coordinada, por lo que ha de estar garantizada la correcta gobernanza de esta infraestructura. Esta aproximación está orientada a procesamiento con redes neuronales, pero también se están desarrollando técnicas alternativas para hacer Aprendizaje Federado Vertical, como son las que utilizan los árboles de decisión federados.
Más material sobre protección de datos desde el diseño e inteligencia artificial en la sección Innovación y Tecnología de la web de la AEPD:
- 10 Malentendidos sobre el Machine Learning (Aprendizaje Automático)
- Requisitos para Auditorías de Tratamientos que incluyan IA
- Adecuación al RGPD de tratamientos que incorporan Inteligencia Artificial
- Guía de Privacidad desde el Diseño
- Post: Privacidad desde el diseño: Computación segura multi-parte, compartición aditiva de secretos
- Post: Ingeniería de la Privacidad
- Post: Inteligencia Artificial: Sistema vs. tratamiento, medios vs. finalidad