Anonimización y seudonimización (II): la privacidad diferencial
En la búsqueda de un equilibrio entre la explotación legítima de la información y el respeto a los derechos individuales han surgido estrategias encaminadas a preservar la utilidad de los datos al tiempo que se respeta la privacidad de las personas. Una de ellas es la privacidad diferencial, que trata de establecer garantías de protección de datos desde el diseño mediante la implementación práctica de estrategias de abstracción de la información.

El valor estratégico de los datos personales para empresas y organizaciones es evidente. Sin embargo, es igualmente innegable el riesgo que el tratamiento masivo de datos personales supone para los derechos y libertades de los individuos y para nuestro modelo de sociedad. Por ello, es preciso adoptar las garantías necesarias para que los tratamientos realizados por los distintos responsables no supongan una injerencia en la privacidad de las personas. En la búsqueda de un equilibrio entre la explotación legítima de la información y el respeto a los derechos individuales, surgen estrategias encaminadas a preservar la utilidad de los datos al tiempo que se respeta su privacidad. Una de estas estrategias es la privacidad diferencial.
La oficina del Censo de los Estados Unidos, para garantizar la precisión de sus estadísticas, impedir que la información personal se revele incluso a través de las mismas, y así aumentar la confianza de los ciudadanos en la seguridad de los datos que proporcionan, aplica privacidad diferencial.
La privacidad diferencial puede encuadrarse dentro de una de las técnicas de mejora de la privacidad, o PET (Privacy Enhancing Technologies), dirigidas a establecer garantías de protección de datos desde el diseño mediante la implementación práctica de estrategias de abstracción de la información. Tal y como lo describe su creadora, Cynthia Dwork, la privacidad diferencial permite garantizar, mediante la incorporación de ruido aleatorio a la información original, que en el resultado del proceso de análisis de los datos a los que se ha aplicado esta técnica no hay pérdida en la utilidad de los resultados obtenidos. Tiene su fundamento en la Ley de los Grandes Números, un principio estadístico que establece que cuando el tamaño de la muestra crece, los valores promedios que se derivan de la misma se aproximan al valor medio real de la información. De esa forma, la adición a todos los datos de un ruido aleatorio permite compensar estos efectos y producir un valor “esencialmente equivalente”.
El concepto “esencialmente equivalente” no significa que el resultado obtenido sea idéntico, sino que se refiere a que el resultado concreto a partir del análisis que se deriva del conjunto original de datos, y el resultado del conjunto al que se ha aplicado privacidad diferencial son, funcionalmente, equivalentes. Esta circunstancia permite incorporar la “negación plausible” de que los datos de un sujeto concreto estén en el conjunto de datos objeto de análisis. Para ello, el patrón de ruido incorporado a los datos ha de estar adaptado al tratamiento y los márgenes de exactitud que es necesario obtener.
El comportamiento descrito permite extraer, a primera vista, dos conclusiones importantes:
- Esta estrategia busca proteger los resultados del análisis de la información, que es la que se va a divulgar. Por tanto, no altera los datos originales, sino que actúa sobre el proceso de transformación o algoritmo de consulta y publicación de los datos analizados.
- Como consecuencia, y a diferencia de otras técnicas de garantía de la privacidad, no se requiere un análisis detallado de otras posibles fuentes de datos que podrían ser utilizadas para hacer vinculaciones con los datos de entrada ni de los posibles modelos de ataque empleados. Con esta técnica, la estrategia de mejora de la privacidad de la información se centra en el proceso de análisis de los datos empleado y no en las características de los datos en sí.
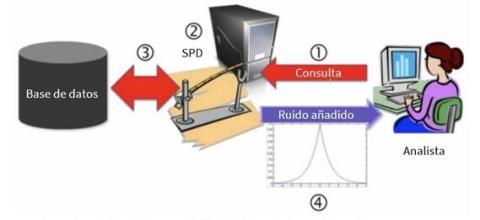

Imagen tomada de la nota de Microsoft “Differential Privacy for Everyone”
En concreto, la privacidad diferencial se apoya en el empleo de funciones matemáticas (también llamadas mecanismos) que añaden ruido aleatorio a los resultados de la consulta realizada. De esta forma, es posible precisar el nivel de confianza de los resultados a partir del parámetro ɛ o presupuesto de privacidad, que establece el equilibrio entre la precisión del resultado de la consulta (exactitud) y la protección de la información consultada (privacidad). Dicho de otro modo, el ruido incorporado enmascara la diferencia que existe entre el escenario de análisis real, que incluiría todos los registros, y el escenario de exclusión en el que han sido eliminados del conjunto global de los datos asociados al sujeto, de manera que el resultado obtenido se diferencia únicamente en el ruido incorporado que viene fijado por el valor de ɛ.
La gran ventaja de esta técnica es que la pérdida de privacidad, al igual que la precisión del análisis, pueden ser cuantificadas de forma objetiva, así como el riesgo de privacidad acumulado como consecuencia de sucesivas consultas realizadas sobre un mismo conjunto de datos. Matemáticamente expresado, el análisis se realiza considerando dos bases de datos: BD1 al conjunto completo de los datos y BD2 al conjunto de los datos con exclusión de un registro. La razón de la probabilidad de obtener un resultado R al aplicar un mecanismo de consulta Ŋ sobre BD1 sobre aplicar Ŋ sobre BD2 y obtener el mismo resultado se expresa como:
Pr[Ŋ (BD1) = R] / Pr [Ŋ (BD2) = R] < e ɛ
En el caso particular de que ɛ=0 nos encontraremos ante la privacidad absoluta como consecuencia de la propia definición de la privacidad diferencial: si ɛ=0, Pr[Ŋ (BD1) = R] = Pr [Ŋ (BD2) = R] con lo que el mecanismo Ŋ será totalmente independiente del subconjunto de datos de análisis seleccionado. Si ɛ es distinto de cero, pero con un valor lo suficientemente pequeño que permite aproximar la razón a 1, nos encontramos ante un escenario de privacidad diferencial.
La pregunta obvia es cómo se calcula objetivamente el valor del ruido que es necesario añadir para tener un valor obtener un valor de ɛ que preserve el resultado dentro del margen de utilidad.
Para ello es necesario tener en cuenta otro concepto que es el de sensibilidad global, que se puede derivar de la medida del peso concreto de un registro sobre el resultado de la consulta. En el caso de valores numéricos, es la diferencia máxima entre dos conjuntos de datos adyacentes, o lo que es lo mismo, aquellos que sólo difieren en uno de los registros. El valor del ruido que añade el mecanismo Ŋ viene condicionado por la sensibilidad global, pudiendo expresarse como:
Δ Ŋ = max [Ŋ (BD1) - Ŋ (BD2)]
En general, la privacidad diferencial funciona mejor con aquellos tipos de análisis con una sensibilidad global baja, en tanto y cuanto que, al añadir ruido, es posible mantener la privacidad de los datos sin distorsionar el valor del resultado real de la consulta por encima del umbral de utilidad.
Existen diferentes tipos de análisis a los que se puede aplicar privacidad diferencial: contabilización de ocurrencias, histogramas, regresiones lineales, funciones de distribución acumulativa, aprendizaje automático, etc., utilizados en aplicaciones prácticas más allá de las ya conocidas de Google, Apple o Microsoft como, por ejemplo, Uber en el análisis de la distancia de los trayectos. Otro ejemplo práctico del uso de la privacidad diferencial es el de la monitorización de los datos de frecuencia cardíaca recogidos a través de un wearable. El dispositivo inteligente identifica puntos destacados en los flujos de datos para después, aplicando privacidad diferencial local, perturbarlos agregando ruido antes de enviarlos al servidor para su reconstrucción, análisis y almacenamiento.
Puede ampliar información sobre ingeniería de la privacidad y otras técnicas utilizadas en la protección de datos desde el diseño en el sitio web ‘Innovación y Tecnología’ de esta Agencia, así como en nuestro blog:
10 Malentendidos relacionados con la anonimización
Introducción al hash como técnica de seudonimización de datos personales
La K-anonimidad como medida de privacidad
Orientaciones y garantías en los procedimientos de Anonimización de datos personales
Anonimización y seudonimización


